
Overview:
Aadhar card OCR is a common yet challenging problem in the Indian digital ecosystem. This guide walks you through building an Aadhar Card Data Extraction WebApp using Python, Django, and Tesseract OCR.
OCR (Optical Character Recognition) enables text extraction from scanned documents and images. However, Indian identity documents like the Aadhar card pose unique challenges due to:
Multiple languages (English + regional)
Non-uniform layouts
Low-resolution or blurred scans
Presence of QR codes and signatures
In today’s digital age, automating the extraction of text from official documents like Aadhaar cards has become increasingly important. While it might sound straightforward, implementing an OCR-based solution comes with its own set of challenges. This blog walks you through the obstacles and their resolutions when building an Aadhaar Card Data Extraction WebApp using Python, Django, and Tesseract.
Aadhar Card OCR (Optical Character Recognition) is essential for digitizing information from India’s widely used identity document. However, the process comes with significant challenges like multilingual text, poor image quality, and non-standard layouts. This guide will walk you through implementing an efficient OCR solution using Python, Django, and Tesseract.
What is OCR?

An Aadhar Card OCR (Optical Character Recognition)is an AI-based technology specifically designed and trained to extract data from scanned images or PDF’s of Aadhar cards
Why Aadhaar Card OCR?
Aadhaar cards, issued by the Indian government, are a common identity document. Automating their text extraction can streamline processes in various industries, such as finance, healthcare, and e-governance.
However, extracting accurate data from Aadhaar cards isn’t as easy as it seems. Let’s dive into the challenges and solutions encountered during this journey.
Quick Overview
There are several frameworks, tools, libraries for extracting text from images:
1. Optical Character Recognition (OCR) Technologies
OCR is a widely used technology for extracting text from images.
Traditional OCR techniques involve:
Template Matching: Comparing input images with predefined character templates.
Modern OCR tools like Tesseract OCR, Google Vision API, and EasyOCR provide accurate text extraction by utilizing deep learning and computer vision techniques.
2. Aadhar Card OCR and Text Extraction
Aadhar cards have a standardized format but pose challenges like:
Low image quality and distortions
Different fonts and orientations
•Presence of background noise and artifacts
•Hybrid Models (OCR + NLP) – Using Natural Language Processing (NLP) for refining extracted text, correcting errors, and formatting data.
3. Django Framework for Web-based OCR Applications
Django, a Python-based web framework, provides:
•Scalability: Easily handles multiple file uploads.
•Security: Protects sensitive Aadhar data.
•Integration with OCR tools: Seamless connection with Tesseract OCR, OpenCV, and cloud-based APIs.
4. Python Programming Language: Python is a multi purpose programming and high-level language commonly used for data science and machine learning applications.
5. Django: Django is a high-level python web framework that enables rapid development of secure and scalable web applications . It follows the Model View Template(MVT) architecture and comes with built in features like authentication, admin panel, database management.
6. OpenCV: It is an open source computer vision and machine learning library designed for real time image and video processing .
7. Tesseract OCR: An open-source OCR engine that supports over 100 languages. Suitable for extracting text from scanned documents, images, or PDFs. Python wrapper pytesseract allows seamless use with Python. High accuracy, supports customization through training datasets.
Django files align with the MTV (Model-Template-View)
- Model (M)
Purpose: Defines the data structure of your application.
Explanation: In Django, the Model is responsible for the data layer. This file contains Python classes that represent database tables. Each class attribute corresponds to a database field, and Django automatically creates the database schema based on these models.
models.py
The models.py file defines the structure of the database table where extracted data is stored. In this case, it includes fields for storing Aadhaar card details - View (V)
Purpose: Handles the logic of the application and responds to user requests.
Explanation: In Django, the View is where business logic resides. It acts as a controller in the traditional MVC pattern. A view receives user requests, processes them (with the help of models), and returns a response (usually by rendering a template).
Everything that we discussed above step by step code will be included in the views.py file - Templates(T)
Templates are used to render HTML pages dynamically based on data passed from views. In this case, the template displays the form for uploading images and shows extracted data along with historical records. - Displays a form to upload images.
- Shows extracted data (name, year of birth, Aadhaar number, address, and raw text).
- Lists historical records retrieved from the database.
- URLs (Routing)
Purpose: Maps URLs to views.
Explanation: Django’s URLs file links the incoming web requests to specific views. In this file, you define URL patterns that point to your views, essentially creating routes for the application.
Project-Level urls.py
Location: Found in the root directory of the Django project (e.g., myproject/urls.py).
Purpose: Acts as the central URL configuration for the entire project. It routes incoming requests to specific app-level urls.py files or directly to views. - Uses include() to delegate URL routing to app-level configurations.
- Provides a clear structure for managing multiple apps within a single project.
- App-Level urls.py
- Location: Found in individual app directories (e.g., myapp/urls.py).
- Manages URLs specific to the app, making it easier to organize and maintain routes for each app independently
- Defines URLs specific to the app’s functionality.
- Can be included in the project-level urls.py using include() for modularity.
- App-level urls.py files define specific routes and link them to corresponding views.
- How They Work Together:
- The project-level urls.py delegates requests to app-level urls.py files using include().
- Forms – forms.py
Purpose: Handles user input, validation, and processing.
Explanation: In Django, Forms are used to handle user input, perform validation, and manage data. Forms are defined in the forms.py file and can be used to create or update model instances. - Settings – settings.py
Purpose: Configures the Django project.
Explanation: The Settings file contains global configuration for the entire Django project, such as database settings, installed apps, middleware, templates, static files, and more
Architecture of Proposed System
Diagram illustrating the process flow
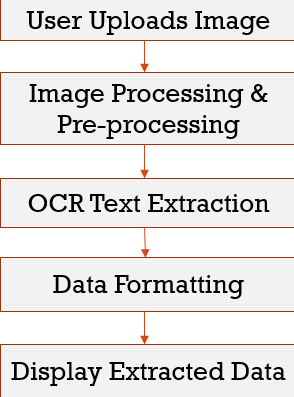
The Aadhar Card Data Extraction Process :
Extracting data from an Aadhar card using AI-based OCR involves several key steps. The process begins with image acquisition, where a scanned copy or photograph of the Aadhar card is uploaded; the file can be a PDF as well. The OCR software then processes the image to enhance readability by removing any background noise and correcting distortions.
Once the image is pre-processed, the OCR engine scans the document and recognizes the text. The extracted data is then structured into predefined fields, ensuring that each piece of information, such as the Aadhar number, name, age, gender, and address, is correctly categorized. After the text is extracted, the system validates the information by cross-checking it with predefined data formats. Finally, the structured data is exported for integration into various applications, such as customer onboarding systems, KYC verification processes, and digital record management solutions.
Challenges in Aadhaar OCR Implementation
1. Handling Pytesseract Dependencies
The Problem
- Tesseract-OCR Installation: Configuring Tesseract on different systems can be tricky.
- Environment Variables: The OCR engine requires proper path configuration to function.
The Solution
Using ChatGPT, I resolved configuration issues by:
- Adding Tesseract’s installation directory to the system’s environment variables.
- Manually setting the path in the Python code:
pytesseract.pytesseract.tesseract_cmd = r'C:\Program Files\Tesseract-OCR\tesseract.exe'This ensured smooth integration with Pytesseract.
2. OCR Limitations

The Problem
- Unintended Text Extraction: Pytesseract sometimes reads background patterns as characters.
- Irregular Formats: Variations in Aadhaar layouts make it difficult to create a one-size-fits-all extraction logic.
- Misinterpreted Characters: Issues like confusing ‘O’ with ‘0’ or ‘1’ with ‘I’ are common.
The Solution
- Preprocessing Images: Leveraging OpenCV for image enhancement. For example:
- Converting images to grayscale:
gray_img = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)- Applying adaptive thresholding:
binary_img = cv2.adaptiveThreshold(
gray_img, 255, cv2.ADAPTIVE_THRESH_GAUSSIAN_C, cv2.THRESH_BINARY, 11, 2
)- Custom Regex Patterns: Using tailored regular expressions to filter and extract Aadhaar-specific data.
3. Handling Multilingual Text
The Problem
- Aadhaar cards often contain regional languages alongside English.
- Pytesseract’s default configuration struggles with these multilingual texts.
The Solution
- Downloading and configuring appropriate language packs in Tesseract.
- Using Pytesseract’s language parameter:
text = pytesseract.image_to_string(image, lang='eng+hin')4. Integration with React.js
The Problem
- Frontend-Backend Coordination: Ensuring seamless processing of images uploaded via React.js.
- Error Handling: Meaningful error messages for issues like unsupported formats or failed extractions.
The Solution
- Implementing an API Endpoint in Django to process images:
@api_view(['POST'])
def extract_data(request):
if 'image' not in request.FILES:
return Response({'error': 'No image provided'}, status=400)
# Process and return extracted data- Displaying intuitive frontend error messages using React state management.
5. Image Quality Issues

The Problem
- Low Resolution: Blurry or poor-quality images reduce OCR accuracy.
- Skewed Images: Misaligned documents make it hard for OCR engines to interpret text.
The Solution
- Preprocessing images to improve clarity:
- Using deskewing algorithms to align the image.
- Enhancing resolution with OpenCV’s interpolation techniques.
6. Performance Optimization
The Problem
- File Size Constraints: Large files slow down processing.
- OCR Speed: Extracting text from high-resolution images can take significant time.
The Solution
- Resizing images while maintaining clarity:
resized_img = cv2.resize(image, (width, height), interpolation=cv2.INTER_AREA)- Implementing asynchronous processing in Django using Celery and Redis.
Tips for Improving OCR Accuracy
This are the tips for Improving OCR Accuracy:
- Enhance Input Quality: Use high-resolution images with good lighting.
- Train Tesseract Models: Custom training improves recognition of Aadhar-specific fonts.
- Use Image Filters: Techniques like histogram equalization improve clarity
- Encourage JPEG/PNG over PDF
- Use both image_to_string() and image_to_data() from Tesseract for fine-grained control
- Experiment with different image preprocessing techniques like adaptive thresholding, morphological transforms
Key Features of the Aadhaar OCR WebApp
- Automated Data Extraction: Reads and extracts Aadhaar details like Name, Year of Birth, Address, and Aadhaar Number.
- Error Handling: Provides detailed feedback for unsupported images.
- Data Validation: Ensures extracted information follows the Aadhaar format.
Step by Step Python, Django & Tesseract Implementation
- Tesseract Installation & Configuration
pip install pytesseract Pillow opencv-python numpy
2. Import necessary Libraries
from django.shortcuts import render
from django.core.files.storage import FileSystemStorage
import pytesseract
from PIL import Image
import cv2
import re
import os
import numpy as np
Libraries used:
pytesseract: Tesseract binding for Python
opencv-python: Preprocessing the images
Pillow: Image handling
Django: Web framework
3. Configure Tesseract Path
pytesseract.pytesseract.tesseract_cmd = r”C:\Program Files\Tesseract-OCR\tesseract.exe”
4. View Function
aadhar_number”: aadhar_number,
“name”: name,
“dob”: dob,
“gender”: gender,
“address”: address,
“ocr_text”: text,
5. Upload_form submission:
<!DOCTYPE html>
<html>
<head>
<title>Upload Aadhaar Card</title>
</head>
<body>
<h2>Upload Aadhaar Card Image</h2>
<form action=”/upload/upload/” method=”post” enctype=”multipart/form-data”>
{% csrf_token %}
<label for=”aadhar_image”>Upload Aadhar Card Image:</label>
<input type=”file” name=”aadhar_image” id=”aadhar_image” required>
<button type=”submit”>Upload and Extract</button>
</form>
</body>
</html>
6. Open and Process Image:
def preprocess_image(image_path):
“””Preprocess the image to improve OCR accuracy.”””
img = cv2.imread(image_path, cv2.IMREAD_GRAYSCALE) # Convert to grayscale
img = cv2.bilateralFilter(img, 9, 75, 75) # Reduce noise while keeping edges
_, img = cv2.threshold(img, 0, 255, cv2.THRESH_BINARY + cv2.THRESH_OTSU) # Apply adaptive thresholding
return Image.fromarray(img) # Convert to PIL Image for OCR processing
7. Extract Specific Data using Regular Expressions:
def extract_aadhar_data(image_path):
“””Extract details like Name, Aadhaar Number, DOB, Gender, Address.”””
try:
img = preprocess_image(image_path)
text = pytesseract.image_to_string(img, lang=’eng+hin’, config=’–psm 4′)
print(“OCR Output:\n”, text) # Debugging: Print extracted text
# Extract Aadhaar Number
aadhar_match = re.search(r’\d{4}\s\d{4}\s\d{4}’, text)
aadhar_number = aadhar_match.group(0) if aadhar_match else None
# Extract Name
name_match = re.search(r'(?:Name|नाम)\s*[:\s]*([A-Z\s]+)’, text)
if name_match:
name = name_match.group(1).strip()
else:
# Fallback: Pick first uppercase line with 2-4 words
lines = text.split(“\n”)
probable_names = [line.strip() for line in lines if re.match(r”^[A-Z\s]+$”, line) and 2 <= len(line.split()) <= 4]
name = probable_names[0] if probable_names else “Name not found”
# Extract DOB
dob_match = re.search(r'(DOB|जन्म तिथि)\s*[:\s]\s(\d{2}/\d{2}/\d{4})’, text, re.IGNORECASE)
dob = dob_match.group(2) if dob_match else text.split(‘\n’)[2].strip()
# Extract Gender
gender_match = re.search(r'(Gender|लिंग)\s*[:\s]\s([A-Za-z]+)’, text, re.IGNORECASE)
gender = gender_match.group(2).strip() if gender_match else text.split(‘\n’)[3].strip()
# Extract Address
address_match = re.search(r'(Address|पता)\s*[:\s]\s(.+)’, text, re.IGNORECASE | re.DOTALL)
address = address_match.group(2).strip() if address_match else text.split(‘\n’)[4].strip()
8.forms.py
from django import forms
class UploadForm(forms.Form):
document = forms.ImageField()
9. Result :
result.html:
{% if data %}
<h1>Extracted Aadhar Details</h1>
<p>Aadhar Number: {{ data.aadhar_number }}</p>
<p>Name: {{ data.name }}</p>
<p>Date of Birth: {{ data.dob }}</p>
<p>Gender: {{ data.gender }}</p>
<p>Address: {{ data.address }}</p>
<h2>Row Output:</h2> <pre>{{ data.ocr_text }}</pre> {% else %}
<p>Data extraction failed.</p>
{% endif %}
10. QR Code Parsing (Optional but Recommended)
Aadhar cards contain an embedded QR code with structured XML data.
from pyzbar.pyzbar import decode
from xml.etree import ElementTree as ET
def parse_qr_data(img_path):
img = Image.open(img_path)
decoded_objects = decode(img)
if decoded_objects:
qr_data = decoded_objects[0].data.decode('utf-8')
try:
root = ET.fromstring(qr_data)
return {
"name": root.attrib.get('name'),
"dob": root.attrib.get('dob'),
"gender": root.attrib.get('gender'),
"uid": root.attrib.get('uid'),
}
except ET.ParseError:
return None
return NoneProject Directory Structure:
aadhar_extraction/ # Django Project Root
├── aadhar_extraction/ # Project Configuration Package
│ ├── init.py
│ ├── asgi.py
│ ├── settings.py
│ ├── urls.py
│ ├── wsgi.py
│
├── extractor/ # Django App for OCR & Processing
│ ├── init.py
│ ├── admin.py
│ ├── apps.py
│ ├── forms.py
│ ├── models.py
│ ├── tasks.py
│ ├── tests.py
│ ├── urls.py
│ ├── utils.py
│ ├── views.py
│ ├── migrations/ # Django Migrations
│ └── templates/ # HTML Templates
│ ├── result.html
│ ├── success.html
│ ├── test.html
│ ├── upload_form.html
│
├── media/ # Uploaded media (images)
├── db.sqlite3 # SQLite Database
├── manage.py # Django Management Script
├── processed.png # Example of processed output image
Final words
By combining Django for backend, Tesseract for OCR, and OpenCV for preprocessing, you can build a solid Aadhar card OCR web application. For enterprise-grade performance, consider upgrading to Google Cloud Vision, AWS Textract, or EasyOCR for multi-language support.
FAQs
Q1. Can this system handle low-quality images?
Yes, by applying OpenCV preprocessing techniques like denoising and thresholding, the app improves OCR results.
Q2. Does it support regional languages?
Yes, you can configure Tesseract with additional language packs to handle multilingual text.
Q3. How do I install Tesseract-OCR?
Install it from Tesseract’s official page and add it to your system’s PATH.
Conclusion
Building an Aadhaar Card OCR WebApp with Python, Django, and Tesseract can seem daunting due to the challenges of OCR technology. However, by leveraging tools like OpenCV and thoughtful preprocessing, you can create an efficient and reliable solution.
This guide covered common obstacles and practical solutions to streamline your development process. Start building your Aadhaar OCR solution today and automate text extraction like a pro!
Next Steps
Add authentication & history tracking for uploads
Store OCR results in a PostgreSQL DB
Validate extracted data via regex and checksum
Dockerize and deploy on AWS EC2 or Heroku

Leave a Reply